How we made sure your system cannot brick during an OTA update
FullMetalUpdate is the first open-source and fully integrated solution for updating your IoT devices flexibly and robustly Over the Air (OTA). Yet even with control and availability, an OTA update might still fail and a device may end up bricked, not only without the update but entirely out of action, too.
With this in mind, Witekio’s Director of Technology Cédric Vincent asked me to add a rollback functionality to FullMetalUpdate. This new functionality needed to ensure that even if an OTA update failed there would be no device downtime and that the device would be unbrickable.
Sounds straightforward, but there’s a catch.
Recall that FullMetalUpdate makes a distinction between updating the target OS and the applications that runs on it. As a consequence, rolling back each entity is a problem of its own. The common solution? OSTree. In adding rollback to FullMetalUpdate, we took advantage of the Git-like philosophy of OSTree: having several commits also means that we can dive deeper on a given one.
Let’s take a closer look.
Rolling Back the Operating System
An OTAS update of an OS may fail for any number of reasons. We first had to define the behavior of our FullMetalUpdate rollback feature, and we decided to select the following:
- if the update fails 5 times, we rollback and feedback to the server with a negative result on the Hawkbit interface;
- if the update succeeds, we feedback to the server positively.
For clarity, we consider an OTA update to be successful when it has reached the FullMetalUpdate client.
Note that OSTree cannot work on its own to update the OS. In our case, there are two other entities that also ensure the proper deployment of updates. The first one is U-boot, the bootloader, and the second one is our FullMetalUpdate client.
U-boot is a bootloader recognized in the field of embedded systems for its wide selection of supported cards, and because it allows the developer to customize the way the card is booted. U-boot defines an environment that it uses to start the card. This environment, loaded from dead memory in RAM, is composed of variables, containing either a value or a command. U-boot is capable of executing a number of basic commands (such as loading the core from the SD card into RAM) but also performing logical operations (such as “if,” “else if,” “not,” etc. like a basic shell).
OSTree, at its core, makes use of the kernel command line to know on which deployment it has to boot. At boot time, U-boot will load OSTree’s environment variable in /boot/loader/uEnv.txt. This file contains crucial information needed by OSTree for the new deployment:
kernel_image=/ostree/poky-<hash>/vmlinuz
fdt_file=/ostree/poky-<hash>/devicetree
ramdisk_image=/ostree/poky-<hash>/initramfs
bootargs=ostree=/ostree/boot.0/poky/<hash>/0
kernel_image=/ostree/poky-<hash>/vmlinuz
fdt_file=/ostree/poky-<hash>/devicetree
ramdisk_image=/ostree/poky-<hash>/initramfs
bootargs=ostree=/ostree/boot.0/poky/<hash>/0
kernel_image, fdt_file, and ramdisk_image are the kernel images, ramdisk image and device tree, respectively, that U-boot will load in memory for initialization. bootargs are the command line arguments that U-boot includes in the kernel command line.
When an update occurs, OSTree will change /boot/loader/uEnv.txt to:
kernel_image=/ostree/poky-<hash>/vmlinuz
fdt_file=/ostree/poky-<hash>/devicetree
ramdisk_image=/ostree/poky-<hash>/initramfs
bootargs=ostree=/ostree/boot.1/poky/<hash>/0
kernel_image2=/ostree/poky-<hash>/vmlinuz
fdt_file2=/ostree/poky-<hash>/devicetree
ramdisk_image2=/ostree/poky-<hash>/initramfs
bootargs2=ostree=/ostree/boot.1/poky/<hash>/1
kernel_image=/ostree/poky-<hash>/vmlinuz
fdt_file=/ostree/poky-<hash>/devicetree
ramdisk_image=/ostree/poky-<hash>/initramfs
bootargs=ostree=/ostree/boot.1/poky/<hash>/0
kernel_image2=/ostree/poky-<hash>/vmlinuz
fdt_file2=/ostree/poky-<hash>/devicetree
ramdisk_image2=/ostree/poky-<hash>/initramfs
bootargs2=ostree=/ostree/boot.1/poky/<hash>/1
All the variables ending with 2 are historic arguments which were used to boot into the previous deployment, with the remaining variables representing the new update. By playing with U-boot environment variables we can make use of this knowledge to rollback to the previous deployment.
At boot time, a custom script is executed by U-boot. This is done by loading this script from the MMC, and then the execution is passed to it. The script works as follows:
The system boots…
U-boot environment variables are loaded…
if init_var is not set:
success = 0 # this deployment is not yet successful
trials = 0 # trials is the number of times we tried to boot
init_var = 1 # init_var is now set
save u-boot environment
load the ostree variables
if success = 1:
boot
elif trials < 5:
trials = trials + 1
save u-boot environment
boot
else
replace bootargs by bootargs2
replace kernel_image by kernel_image2
replace fdt_file by fdt_file2
replace ramdisk_image by ramdisk_image2
save u-boot environment
boot
end if
if init_var is not set:
success = 0 # this deployment is not yet successful
trials = 0 # trials is the number of times we tried to boot
init_var = 1 # init_var is now set
save u-boot environment
load the ostree variables
if success = 1:
boot
elif trials < 5:
trials = trials + 1
save u-boot environment
boot
else
replace bootargs by bootargs2
replace kernel_image by kernel_image2
replace fdt_file by fdt_file2
replace ramdisk_image by ramdisk_image2
save u-boot environment
boot
end if
During an OTA update, the FullMetalUpdate client deletes init_var from U-boot’s environment, which resets the variables success and trials. Then, on each boot, trials are incremented. If the boot fails five times, all the rollback variables (kernel_image2, bootargs2 and so on) replace the original ones, which ensures a proper boot.
Finally, when the OS boots and the client is initialized, it will check whether the system has rolled back or not by comparing the commits of the booted deployment and the distant deployment. Depending on the status of the system, the client will send feedback to the server, indicating that the update was successful or not.
Avoiding a system hang during the OTA update
This rollback feature rests on the hypothesis that the system is able to reboot upon a failure. There are multiple points where this can happen during an OTA update, and we offer a solution for each of them:
- Kernel panics are handled by enabling a hardware watchdog via U-boot configuration. This solution is the most important as many failures end in a kernel panic.
- Systemd drops the target in an emergency mode when there is a critical problem when starting the system services. This is useful for debugging purposes, but it hangs the system at a stage when a network connection might not be available. To enable automatic rebooting at this point, we created an override to the emergency service so that it reboots after 30 seconds if the user doesn’t offer any physical input.
- OSTree has a custom initrd script which mount the proper root filesystem by parsing the kernel command line. Sometimes, for a variety of reasons, this script may fail to mount the filesystem. In that case, the default behavior of the script is to drop into a shell. For the same reasons as the preceding point, we changed this behavior. Instead, it will also reboot after 30 seconds, letting the user choose whether to drop into that shell or not.
If you wish to know more about this feature, you can read the more detailed documentation on the FullMetalUpdate GitHub.
Rolling Back an Application
Rollbacking an application is another story. In FullMetalUpdate, applications are embedded in runc containers. Having a containered application is great for several reasons, and in our case, we take advantage of the fact that the application runs in a separate file system. This file system can be managed with OSTree just like the OS, as if each version of the application is a commit.
Using system notify services
In FullMetalUpdate, all containers are started with systemd through the use of services. This allows for a proper life cycle, CGroups, and the usage of the great API systemd is offering to manage services. Thus, runc containers are started with a service file which can be configured to start or stop the container and execute commands after these jobs. This last point is important as it is the core of the FMU’s rollback feature for containers.
Systemd offers a type of service called notify. This service differs from simple services because it is waiting for a flag coming from the main process (or any child process depending on the configuration) before being switched to an activated mode. The service will start the main process and then wait for this notify signal. If the service either exits without sending the signal (successfully or unsuccessfully) or does not send the signal during a predefined delay, the service is considered to have failed. If the container successfully executes systemd-notify –ready, the service considers the container startup as successful.
It is useful to leverage this feature to determine if the container should rollback to its previous version. As a consequence, the rollback feature for containers is optional. This choice of being an optional feature rather than a default, static feature mainly comes from the fact that containers may vary greatly depending on the types of features they implement.
Using notify services to control the status of applications
First of all, let’s describe how a successful OTA update happens with notify services:
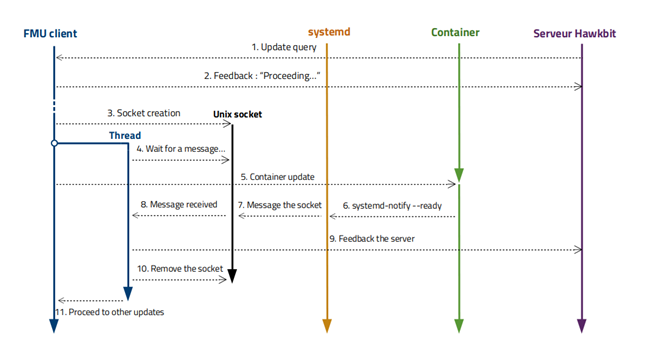
- Update query: The user starts by making an update request for a notify container.
- Feedback: “Proceeding…”: The client sends feedback to the server to let them know that they have received the request.
- Socket creation: After downloading the necessary data, the client creates a Unix communication socket. This socket is used to establish communication between him and systemd.
- Wait for a message: The client creates a thread. This thread is used to wait for a message from systemd regarding the condition of the container, through the previously created socket. This is done in a thread because waiting on a socket is a blocking call, and the client still needs to update the container.
- Container update: The client updates the container with OSTree. The container is started on its new version.
- systemd-notify –ready: When the container has completed its initialization, it executes the systemd-notifyready command. This indicates to systemd that its execution went well.
- Message the socket: Systemd sends a message to the container to let it know that the execution went well.
- Message received: The thread described in step 4 receives the message from systemd. It then decodes this message and considers the initialization successful.
- Feedback the server: The initialization is successful; the client sends positive feedback to the server.
- Remove the socket: After that, the client removes the communication socket.
- Proceed to other updates: The client resumes normal execution and can make further updates.
Now, let’s see a scenario where the container startup fails to send a feedback message before a systemd-defined timeout value. After this timeout, systemd consider the execution of the container as failed. Steps 1 to 5 are exactly the same:
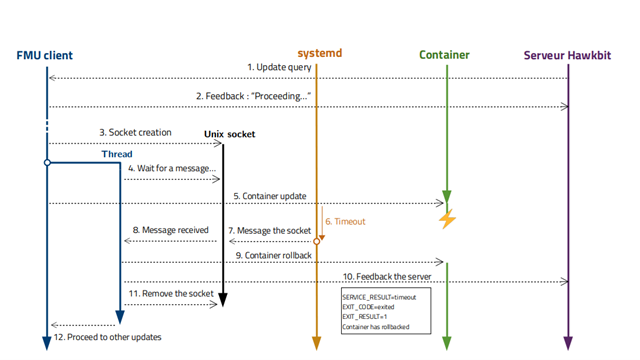
Here’s what happens next:
- Timeout: The container started but did not send the flag.
- Message the socket: After the timeout, systemd considers that the initialization has failed, and stops the execution of the container. Systemd sends a message to the socket informing it that the initialization has failed.
- Message received: The socket receives the message from systemd. The socket decodes the message and concludes that the initialization went wrong.
- Container rollback: The socket tries to rollback the container to the previous commit (this may be the first version of the container, in which case rollback is impossible).
- Feedback to the server: After the possible rollback of the container, the client sends negative feedback to the server. This feedback contains debug information, and information about the rollback of the container.
- Remove the socket: After that, the thread removes the communication socket.
- Proceed to other updates: The client resumes normal execution.
With this design, it is easy to see that we are able to trigger a rollback on an application for which the startup has failed. Of course, there are multiple scenarios that might be the cause of the failure, but all have been tested and are handled by systemd.
If you wish to know more about this feature, you can read the more detailed documentation on the FullMetalUpdate GitHub.
FullMetalUpdate Rollback functionality now allows for 100% uptime for of your device, and also gives the user feedback on the state of the device. It allows the user to take risks without worrying about bricking the device, which is a great feature when working with devices remotely.
This solution is already entirely integrated when building from the build system. Need to enable these features for a specific board? Reach to us on gitter!



