Welcome to this second post about Software Factory. We will be speaking here about infrastructure, automation and a little about DevOps and NoOps culture.
This article will be speaking a lot about tools, if you haven’t read the first article of this serie, you probably should and please do not forget that we are in front of a 70/30 problem. Right technical tools are only 30% of the topic.
A short introduction story
Before going further, let’s start with a short story: My mother always says to me when she sees the state of my school kit pretty empty with only one pencil:
“How do you want to work well at school if you do not have the right tools?”
A sentence full of common sense.
Well, you would be surprised to know how many software guys do not have the right tools they need on a daily basis from their organization and loose time by performing Shadow IT. A lot of organizations think that providing a PC with an email tool, Word and PowerPoint is enough. It can be enough for some Manager but for Software people it is far from covering their needs.
For efficiency and performance, teams need right and efficient tools to achieve their missions. We spent the last decades creating IT functions in silos, focusing on costs, segmenting and dividing competencies, and now, we realize that theses silos and bureaucracy are counterproductive and kill innovation and performance.
Devops movement: a philosophy for performance and innovation
To address this organizational malfunction, the DevOps movement was born and is getting more and more and more popular.
DevOps term is a contraction of Developer and Operational. Lots of people misunderstood the name and thought this position is a mix where people would do Dev jobs together with Ops jobs. If you think like that you will probably have some issues in the future. Ops and Devs don’t do the same jobs, people who have the ability to do both roles are very rare. And when DevOps is thinking like that, it generally ends up by Dev people doing Ops operation in “Cowboys mode”.

DevOps also requires a change in vision. Management will have to stop thinking Dev as R&D and innovation where budgets are opened and Ops as a cost center that should be reduced and compressed, it is the best way to lose control. DevOps is generally a long road for old non-software company, it requires deep changes and processes and human ways of working cannot change in one day.
You’ll known when your company has finished its transformation when you can perform update and deliveries continually and transparently. A simple test you should do is: unleash the Netflix Chaos Monkey tools on your infrastructure if you don’t have any infrastructure outage you’re there.
According to Gene Kim, co-author of The Phoenix Project (the bible book of “IT automation/DevOps”):
“Of course, things are not magic. I don’t mean that all good things will just happen by moving to DevOps, but do you really want to risk the “outcomes” of staying with outdated models that lead to very long deployment cycles when all your competitors move to Agile and DevOps organization?”
This list of companies already practicing DevOps is very long. All major IT players like Amazon, Facebook, Ebay, and Netflix already do that but it is true in a wide variety of markets:
- In distribution: Walmart have a strong DevOps strategy since 2013
- In bank: ING Direct have a strong DevOps strategy since 2015
- In Automotive: companies like Elektrobit, Urban Science or Scania
NoOps : a better implementation of the DevOps philosophy
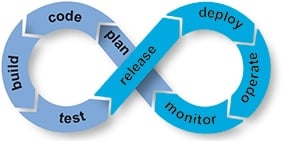 If you seek for DevOps articles, you will probably also see the term NoOps.
If you seek for DevOps articles, you will probably also see the term NoOps.
NoOps movement can be seen as an evolution of the DevOps, like the first it will not simply say that we are no more Ops, it says that Ops are “hidden” for normal use. Ops are handle from the begin, Dev people have access to service, feature for free, without difficulty, IT environment is so automated and abstracted from the underlying infrastructure that there is no need for a dedicated team to manage software in-house.
This means that you have a very powerful/skilled team to architecture and maintain the underlying infrastructure. Things are never magic.
NoOps should be preferred to DevOps, process and automation should be easy and simple to understand, everybody can come into your software factory and start to work without the need of X month of learning curve.
Ok DevOps/NoOps is about culture, process automation and shared knowledge, but how do I implement it?
Like Gutenberg printer was a tool that enabled the cultural change of Enlightenment philosophers, DevOps creates a cultural change that will deeply transform and modernize your company.
There is a wide variety of DevOps tools, it will be a too long list to reference all of them and tools are only a minor part of this cultural change, but we can give some guidelines.
There is an agreement to consider that tools allowing to manage our infrastructure as you manage code are key to implement DevOps concepts.
Infrastructure as Code
Infrastructure as Code is one of these concepts. It means that infrastructure should be treated as code. Server configuration, packages installed, relationship with other servers, should all be modeled with code to be automated and have a predictable outcome, removing manual steps that are prone to errors and allowing to modify or rebuild your infrastructure at any time.
This concept is not really new. IT administrators have been using scripts to automate their infrastructure since the beginning of computer science but everyone would do it their own way. Now there’s some common language used by Puppet, Chef or Ansible that allow you to share and reuse configurations as modules or recipes. Developers and IT guys share a common language and common processes. They are shared across the company, reducing new employees’ learning curve.
Pets vs Cattle
Another concept is Pets vs Cattle: “Old ways” use servers as Pets, “new ways” use them as Cattle.
To be clearer:
- Pets: Servers or server pairs that are treated as unique systems that can never be down. Typically, they are manually build and managed. Examples includes solitary servers, HA load balancer or database systems designed as master/slave
- Cattle: Arrays of more than two servers that are built using automated tools and designed for failure. No one, two, or even three servers are irreplaceable. Typically, during failure events no human intervention is required. The system as “self-healing” features restarting failed servers or replicating data on other servers.
Examples include web server arrays, multi-master systems such as Zookeeper, Etcd or Cassandra. The key factor is that the old redundancy world is having two of everything, the ubiquitous HA pair in the enterprise infrastructure is not enough.
What is required is assuming that failures can and will happen is that every server, every component is able to fail without impacting the whole system. That it is important with this concept or analogy, it helps educating a generation of IT managers, CIO, CDO and others. Servers are too cheap to be counted individually, replace them instead of fixing them.
Where to host your IT/DevOps infrastructure
With the multitude of IT Cloud offers, a lot of companies asks this question. Answer to this question is not really easy as a lot of parameters have to be taken into account. It really depends on the company culture, the size of the company, the actual state of internal IT, CIO/CDO/CTO willingness, …
Below I give some inputs that can maybe help you to make a decision grid between Cloud (SaaS/PaaS), Hybrid and Home-made solution.
Infrastructure outside the company? Data Criticality will be your criteria.
Putting an infrastructure outside the company’s walls is not a new concept. It is to resort to subcontracting (or outsourcing, choose the word you like).
Every time you use subcontracting you share some internal data with an external third party. To ensure control, legal stuff enter in the game with contract and NDA. Nothing new here, but IT infrastructure is something crucial for your company. It is not a tiny part of your company’s data that your share with a third party but probably the whole of your company, massive amount of data where business information, technical information are present. This is something that you should think about. Depending on your size and the importance that you give to your data, you can adopt the” tiny fish” strategy that will pass anyway between the mesh of the nets or not.
The problem actually is that the Cloud offer is concentrated in the hands of a few major American players: Google, Amazon or Microsoft Azure. Regardless the service you use, at the end your data will end in an Amazon S3 bucket or a Google Computer Engine store. And since Edward Snowden revelations, it is now for sure that American governmental organizations with the help of the Patriot Act can have direct access to them. If you work on sensible industry like military industry or you have an Iranian Company in our top customer list, you should probably avoid using Cloud service. Some players in Europe and especially in France like OVH or Ikoula offer some Cloud sovereign solutions. It can be a good alternative if you are worried about that.
Other things you will have to take in account is that, even if “to-big-to-fail” IT company have failures. When S3 bucket has an outage on Amazon US-EAST-1 zone, like it happened in the beginning of 2017, our access to internet will be broken as large part of “our internet” run behind Amazon S3 solution.
Economic point of view
Cloud is cheap. The level of IT concentration of these companies allows them economies of scale that will make them always more competitive than you. It is very difficult to give a real answer without knowing more details about your company’s infrastructure needs. I can just say, compare prices, there can be some big differences, GCE is in average 50% cheaper than Amazon for productive use case.
When you pay for a service, you don’t need to manage obsolescence of the service but you also pay margin of your third party.
At the end of the day, costs are not necessarily so competitive. If you need a huge amount of bandwidth and world redundancy/availability, you will have no choice, in-house solution is economically impossible.
If your bandwidth requirement is acceptable and you only want automated, state of the art IT infrastructure, an in-house solution can be a powerful and economics solution. If you are able to be smart when you design/build of IT infrastructure it can be even cheap.
Don’t do a white check to Dell or HPE, buy reconditioned servers that are compatible with Open Computer Program (an open-hardware program manage by Facebook with help of Google and some other actors), they are cheaper, more powerful and have better power efficiency (use of battery instead of inverter). Take state of art ”OS for datacenter” like Mesos or Kubernetes, find intelligent people who have automation flowing in their blood and you can have your own in-house “Cloud” solution based on open standard. The goods news here is that Open source are everywhere, things are open, known, company communicate on it, you just need to have the right experts to perform System Integration and put all these Open Source blocks with the right glue to build a coherent environment. You don’t need to invest a lot of money in R&D to recreate the “Cloud wheel”, major piece of technologies are already here, opensource and common, simply use them right.
You now have a better view of what is DevOps, the new agile IT organization. It is the brother of the Agile Processes. While Agile methods focus on development, DevOps focuses on Operational and requires to merge Dev and Ops organizations. Again, the key word is automation, for that you will need a good and powerful infrastructure. Investing in automated tools and processes is always beneficial, it will allow you to deliver faster, with a better quality and at the end cheaper.
If you want to ask questions or comment this article, please feel free to do so, I will be happy to read you and comment back. In the next post of my Software factory series, I will come to software testing methodologies.


