DRAM prices up 80–90% in a single quarter.
When a number like that crosses your desk, the temptation may be to wait it out. We understand the instinct. But as we’ll lay out here, this isn’t a brief market correction. It’s a deeper, structural shift, and for OEMs, the window to act before it becomes a crisis is narrowing fast.
To maintain production and profitability, decision makers need to build a robust backup plan, one that uses software flexibility to work around hardware scarcity. This article is our attempt to map out what that plan looks like.
How Did We Get Here?
The memory market has always been cyclical, but what’s happening today is something else. According to Counterpoint Research, DRAM prices surged 80 to 90 percent in a single quarter. That’s not a blip. That’s a structural shift.
Two forces hit at the same time. First, the AI infrastructure build-out. The demand for High Bandwidth Memory (HBM) — the specialized DRAM that feeds GPUs and AI accelerators in data centers — has gone through the roof. The biggest AI players have locked up their chip supply as far out as 2028.
That leaves everyone else (OEMs, industrial device makers, consumer electronics manufacturers) fighting over a dramatically reduced pool of standard DRAM.
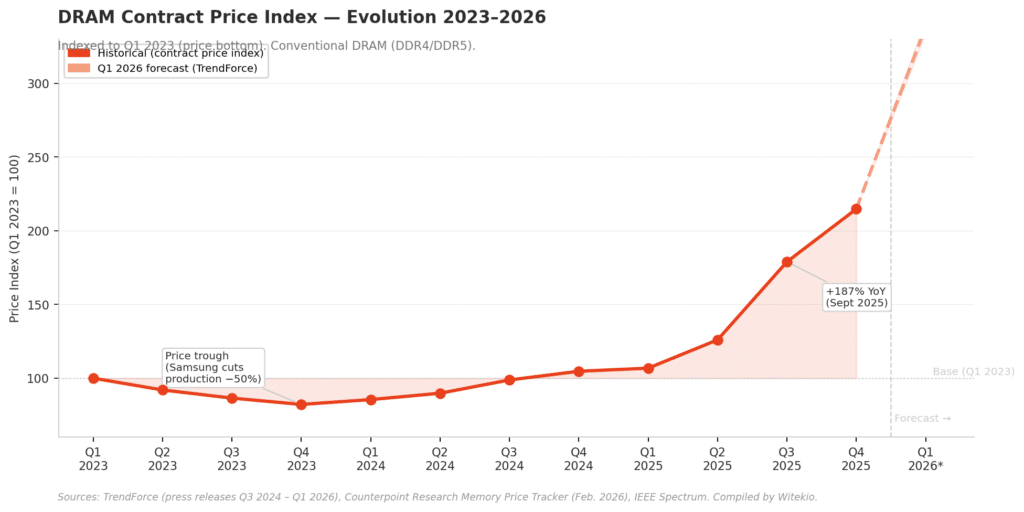
The second force is the industry’s own historical boom-bust cycle*. The price crash of 2022–2023 pushed major manufacturers, including Samsung, to cut production by up to 50% to protect margins. A rational call at the time, but one that contributed to the supply gap we’re seeing now.
While new fabs are being planned and built, experts don’t expect meaningful relief before 2026–2028 at the earliest.
The conclusion is clear: this shortage will last and companies that assume things will return to normal within a few months are taking a strategic gamble they may not be able to afford.
What’s Actually at Stake for OEMs
For OEMs, the immediate risk is existential: the inability to produce profitably, or at all. But beyond supply chain disruption, the crisis reveals a deeper structural vulnerability: the disconnect between hardware and software strategies.
How this crisis plays out will also depend heavily on how OEMs manage it. The companies that will weather this storm are those that stop making hardware-first decisions in isolation and start thinking in terms of software-defined architectures, building flexibility into their stack from the ground up.
A few questions we would push every decision maker to answer today:
- Can I still source the DRAM my current product requires? And at what cost?
- Is my software architecture portable enough to run on a different board if I need to switch?
- Where in my stack can I actually reduce memory consumption? And will it be enough?
- What’s my platform strategy at 3 to 5 years if this shortage holds?
Three Paths Forward: A Decision Framework for OEMs
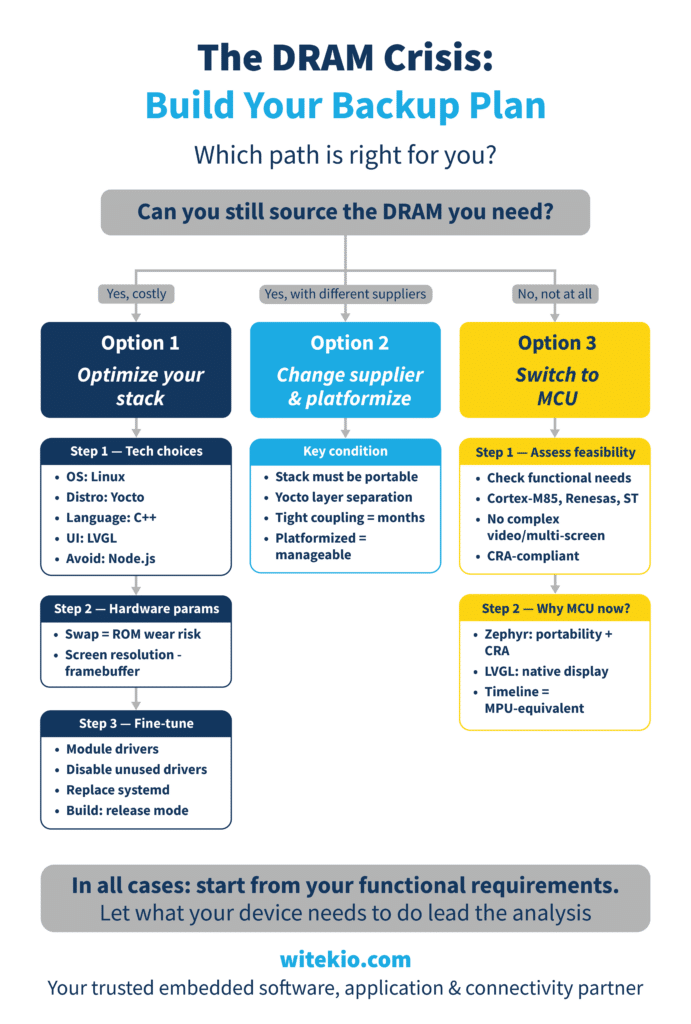
There’s no universal answer to this crisis, but there is a useful starting question: can you still source the DRAM you need? Your answer to that shapes everything else.
Option 1: You can find DRAM, but less of it: optimize your stack
If memory is available but scarce or expensive, the goal is to reduce your footprint without changing your core platform. That means a real audit of your software stack (OS, middleware, UI frameworks, application layers) to find where optimizations are possible.
What isn’t always possible to optimize, but will have a significant impact on RAM consumption, are the choices of software technologies used in the platform. These optimizations are only simple if development hasn’t really started yet, because changing technologies can take several months to years depending on the layer being changed.
Step 1 — Start with technology choices
Technology choices are where the biggest gains are, and where the decisions are hardest to reverse. Here are the key levers to consider:
- Operating system: Linux generally consumes less RAM than Windows and is the natural choice for optimized embedded platforms.
- Distribution: Avoid desktop-oriented distributions like Debian. Ideally, build your own precisely trimmed distribution using a project like Yocto. Depending on the configuration, the memory footprint difference can be significant.
- Dependencies and frameworks: Avoid technologies with many implicit dependencies such as Node.js. Choose frameworks for which you have complete control over what gets pulled in.
- Programming languages: Languages such as C++ where memory consumption can be fully controlled are preferable to interpreted languages like Python.
- UI framework: Using a native graphical framework like LVGL rather than web technologies will have a very significant impact on RAM consumption. We strongly recommend avoiding the use of a web browser, which inherently consumes a large amount of RAM.
Step 2 — Don’t overlook hardware parameters
One often underestimated factor is that hardware choices can significantly impact RAM consumption:
- Swap space: Implementing swap space allows the use of ROM to compensate for limited RAM. However, depending on the type of ROM used, this can lead to rapid degradation and should be evaluated carefully.
- Screen resolution and display quality: Depending on the platform, the frame buffer may reside in RAM, and its size is directly affected by screen resolution and color depth. This is a parameter worth factoring in early.
Step 3 — Fine-tune your existing stack
Once technology choices are locked, generic Linux-level optimizations can still be applied with varying degrees of impact:
- Use module drivers rather than built-in drivers, so they are loaded into RAM only when necessary.
- Disable drivers that are not used.
- Replace systemd with a less resource-intensive init solution.
- Avoid using TmpFS.
- Build in release mode rather than debug mode.
Option 2: You can find DRAM, but with different suppliers: platformize
Memory shortages affect different memory types and suppliers, so it may be possible to find memory, but only if it’s compatible with different MPU models.
Depending on application requirements and hardware needs, using different MPU models can be quite simple, but only if a platform-first approach was followed during software development.
Yocto, for example, natively facilitates support for multiple hardware targets with the same Linux distribution. However, this is only possible if best practices are followed, including proper layer separation and regular updates.
Option 3: You can’t find DRAM at all: consider switching to MCU
If memory simply isn’t available in the volumes you need, switching to a microcontroller removes the supply problem entirely as MCU RAM is embedded directly in the processor and manufactured by a completely different supply chain. It is certainly the most impactful change, as it can require redeveloping an entire platform and often necessitates different skills. But it may be the right call.
Step 1 — Assess feasibility against your functional requirements
Feasibility is fairly straightforward to assess by analyzing the functional and technical requirements of the platform.
Many MPU-based platforms we’ve worked on could have run on MCUs, especially with newer Cortex-M85 processors now available from companies like Renesas and STMicroelectronics.
These processors, even in less powerful variants, are capable of handling reasonably sized screens and offer solid connectivity. From a cybersecurity standpoint, MCUs meet the requirements outlined in regulations such as the European CRA, and generally offer hardware security support comparable to MPUs.
An MPU remains necessary when:
- highly complex animations are required on screen
- multiple screens or high-resolution screens need to be driven
- video streams need to be managed, whether at the capture or display level
- large data streams need to be exchanged over the network
- significant processing power is required, including advanced mathematical calculations.
Step 2 — Why the MCU world has changed
The historical barriers to MCU development (poor portability, weaker security support, starting from scratch on each new platform) are no longer what they were. With RTOSs like Zephyr, those concerns are largely a thing of the past.
Zephyr leverages the latest hardware security capabilities of MCUs, enabling full compliance with CRA requirements. Its development environment and Linux-derived concepts such as hardware description files make platformization genuinely manageable. There is no longer any excuse for not considering MCU development when the functional and technical requirements are aligned.
The Shortage Won’t Wait. Neither Should Your Plan.
There’s no perfect option here , only the one that fits your constraints, your product, and your timeline. But that’s precisely the point: the companies that will come out of this in good shape are not the ones with the best luck on supply. They’re the ones that assessed their situation early, made a clear call, and executed.
The decision tree we’ve outlined isn’t exhaustive, every product has its own architecture, its own dependencies, its own non-negotiables. But in all cases, the right place to start is the same: what does your device actually need to do? Let your functional requirements lead, and the rest of the analysis follows.
If you’re working through this and want an outside perspective, whether that’s pressure-testing your current stack, evaluating a hardware migration, or thinking through what an MCU switch would actually involve, that’s exactly the kind of work we do with OEMs at Witekio.
Sources:
- boom-bust-cycle: as cited in the IEE Spectrum article below
- IEEE Spectrum, “How and When the Memory Chip Shortage Will End”
- Counterpoint Research: Memory Prices Surge Up to 90% From Q4 2025
Your Decision tree for a backup plan